Introduction à Pandas

Qu’est-ce que Pandas ?
Pandas est une bibliothèque Python puissante et flexible utilisée pour la manipulation et l’analyse de données. Elle est particulièrement utile pour les scientifiques qui travaillent avec de grandes quantités de données.
Charger la librairie Pandas
Pour utiliser Pandas, vous devez d’abord l’importer dans votre script Python :
import pandas as pd
Pour une meilleure lisibilité des librairies que vous utiliserez, il est recommandé de les charger dans la première cellule de votre Notebook.
La structure de données principale de Pandas
Un DataFrame est une structure de données bidimensionnelle fournie par la bibliothèque Pandas en Python. Il ressemble à une feuille de calcul Excel, avec des lignes et des colonnes. Chaque colonne peut contenir des types de données différents (nombres, chaînes de caractères, etc.), ce qui le rend très flexible pour manipuler et analyser des données.
Importer les données à partir d’un fichier CSV
Le traitement des fichiers contenant des données est essentiel en programmation Python, en particulier dans le domaine des sciences de données. CSV signifie Comma-Separated Values (valeurs séparées par des virgules). C’est un format de fichier simple utilisé pour stocker des données tabulaires, comme une feuille de calcul Excel.
Pandas fourni des fonctionnalités pour lire des fichiers csv ou en créer.
La première étape pour travailler avec des données est de les charger dans un DataFrame. Supposons que vous avez un fichier CSV nommé data.csv :
Afin de facilité son importation, vous devez placer votre jeu de données dans le même répertoire que votre Notebook.
df = pd.read_csv('data.csv')
Afficher les données
Pour voir la totalité du jeu de données, il faut écrire seulement:
df
Cependant, lorsque le jeu de données comporte trop de données, il est coutume de n’afficher que les premières et dernières lignes pour avoir un aperçu.
Créer un nouvelle cellule pour utiliser la fonction head().
df.head() # Affiche les 5 premières lignes du DataFrame
Créer un nouvelle cellule pour utiliser la fonction tail().
df.tail() # Affiche les 5 dernières lignes du DataFrame
df.head() et df.tail() accepte aussi chacun un paramètre qui correspond au nombre de lignes qui peuvent être affichées.
Exemple: df.head(3) affichera les 3 premières lignes. df.tail(3) affichera les 3 dernières lignes.
L’exemple ci-dessous montre les 5 premières lignes:
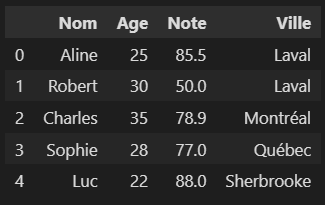
Pour garder l’affichage “Pandas”, il faut créer à chaque fois une nouvelle cellule pour y afficher différentes informations.
Dans le cas contraire, il faut faire une succession de print() dans la même cellule avec vos informations.
Mettre df.head() et df.tail() dans la même cellule n’affichera que la dernière ligne de code exécutée, c’est à dire: df.tail().
Renommer des colonnes
Les colonnes peuvent être renommées pour une meilleure clarté. Dans l’exemple ci-dessous, “Nom” est renommé en “Prénom”.
df = df.rename(columns={"Nom": "Prénom"})
df.head()
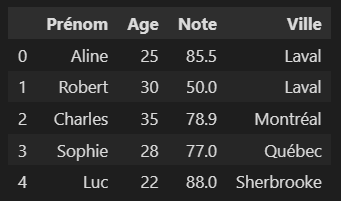
Accéder aux données
Pour accéder directement aux données d’une colonne, il suffit de mettre le nom de votre Dataframe suivi de la colonne entre crochet:
df["Age"] # Accède aux données de la colonne Age
0 25
1 30
2 35
3 28
...
Name: Age, dtype: int64
Pour deux colonnes, il faut englober les colonnes avec des doubles crochets :
df[["Age", "Ville"]] # Accède aux données de la colonne Age et Ville
Sélectionner et filtrer de données
Dans un premier temps, un sous-Dataframe est créé basé sur les colonnes souhaitées:
df_selection = df[["Prénom", "Note", "Ville"]] # Sélectionne les colonnes Prénom, Note et Ville
df_selection
Ensuite, il faut filtrer le sous-Dataframe avec une condition, ce résultat doit être stocké dans une variable qui sera de type Dataframe. Dans cet exemple les notes supérieures à 60 sont affichées:
valeur = 60
df_reussite = df_selection[df_selection["Note"] >= valeur]
df_reussite
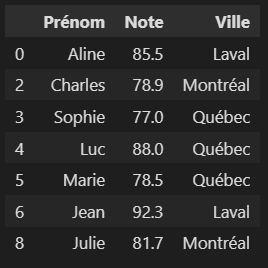
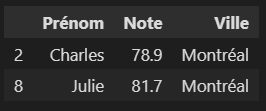
Ci-dessous, le résultat donne les étudiant(e)s de Montréal ayant 60% et plus.
df_reussite_montreal = df_selection[(df_selection['Note'] >= valeur) & (df_selection['Ville'] == "Montréal")]
df_reussite_montreal
Dans les chapitres précédents, il était coutume d’utiliser and et or pour combiner des comparaisons. Avec Pandas, il faut utiliser & pour and et | pour or.
Ajouter et supprimer des colonnes
Pour ajouter une colonne :
df["Session"] = "Automne" # Ajout d'une nouvelle colonne avec la donnée "Automne" pour toutes les personnes présente dans le jeu de données.
df.head()
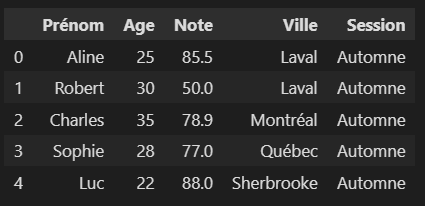
Pour supprimer une colonne :
# Suppression d'une colonne
df = df.drop(columns=["Session"])
df.head()
Informations sur le DataFrame
Pour obtenir des informations générales sur votre DataFrame, telles que le nombre de lignes et de colonnes, les types de données, etc. :
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10 entries, 0 to 9
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Prénom 10 non-null object
1 Age 10 non-null int64
2 Note 10 non-null float64
3 Ville 10 non-null object
dtypes: float64(1), int64(1), object(2)
memory usage: 452.0+ bytes
Nous retrouvons bien les types de variables connus : int, float.
object fait souvent référence au typestr.
Statistiques de base
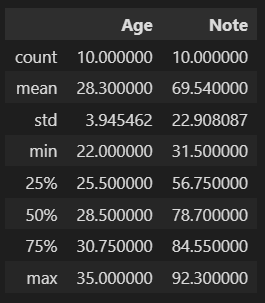
Pandas offre des méthodes simples pour obtenir des statistiques de base sur vos données de type numérique :
df.describe() # Affiche les statistiques descriptives des colonnes numériques
Boucler sur une colonne pour effectuer des agrégats
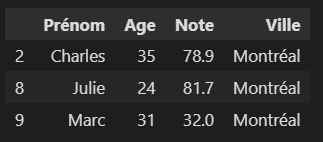
Calculons la moyenne pour les personnes de Montréal.
- On filtre notre jeu de données en rapport avec les personnes de Montréal.
df_montreal = df[df["Ville"] == "Montréal"]
df_montreal
- On calcule la moyenne des notes à l’aide d’une boucle
for
somme_note = 0
for note in df_montreal["Note"]:
somme_note = somme_note + note
moyenne = somme_note / len(df_montreal)
print(f"La moyenne des personnes de Montréal est de {moyenne}%")
La moyenne des personnes de Montréal est de 64.2%
Visualiser des données
Bien que Pandas ne soit pas une bibliothèque de visualisation, il s’intègre bien avec Matplotlib pour créer des graphiques simples.
Nous verrons comment utiliser la bibliothèque Matplotlib pour tracer des graphiques, la semaine prochaine.
Pour tout savoir sur Pandas: Site officiel Pandas.